Spring Native Beta Releaseについて
※ 以前投稿した記事に誤りがあったので投稿し直しています
Spring Native Betaリリース
Spring Nativeとしてリリースされました。まだBeta版(Version 0.9.0)で、spring-projects-experimentalという実験的プロジェクト配下に置かれています。(2020年のSpring IOではSpring GraalVM Nativeと呼ばれていました)
Spring Boot, Spring Cloudなどの各種OSSのNative Imageの作成を行ってくれます。過去にこちらで触れたCloud Native Buildpackを利用したDocker Imageを作成することで、簡単にNative ImageをDockerコンテナで動かすことができるようになりました。
Spring Native を利用したプロジェクトの作成
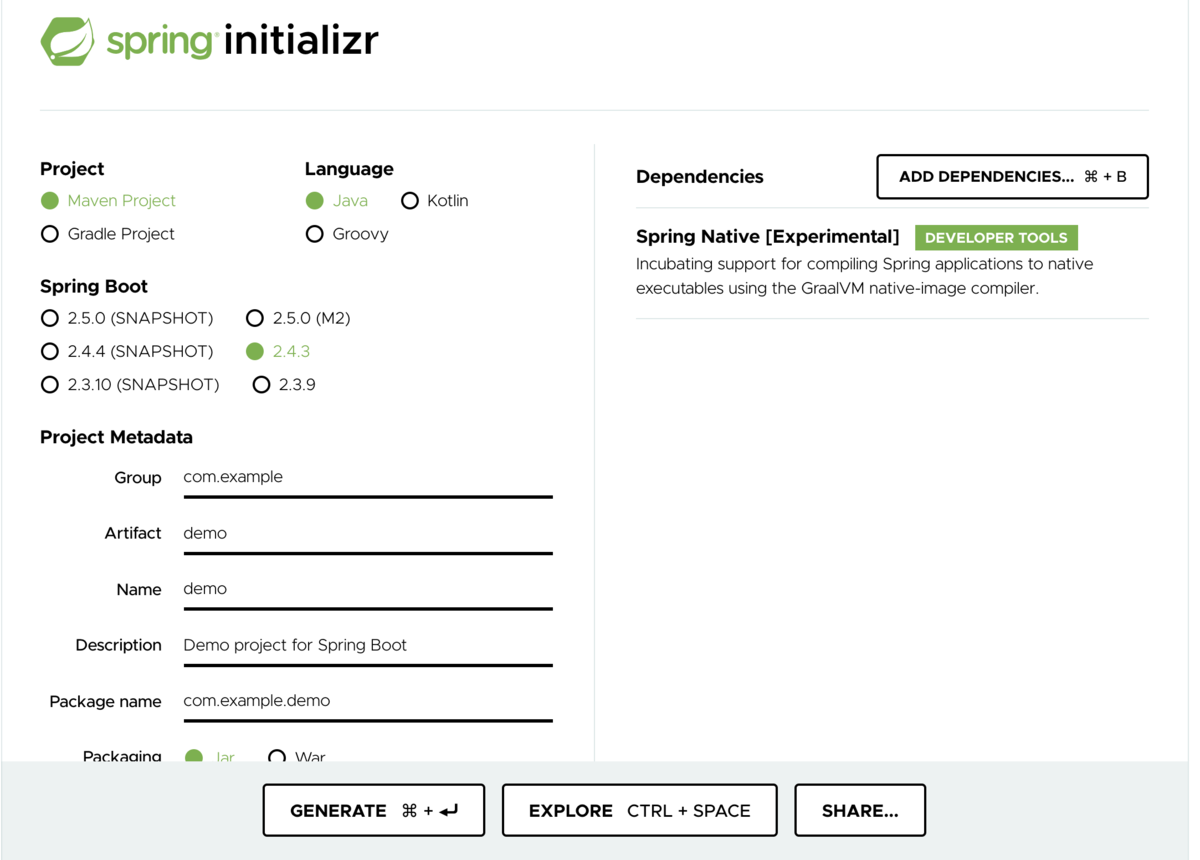
Spring InitilizrですでにSpring Nativeが入っており、選択することができます。
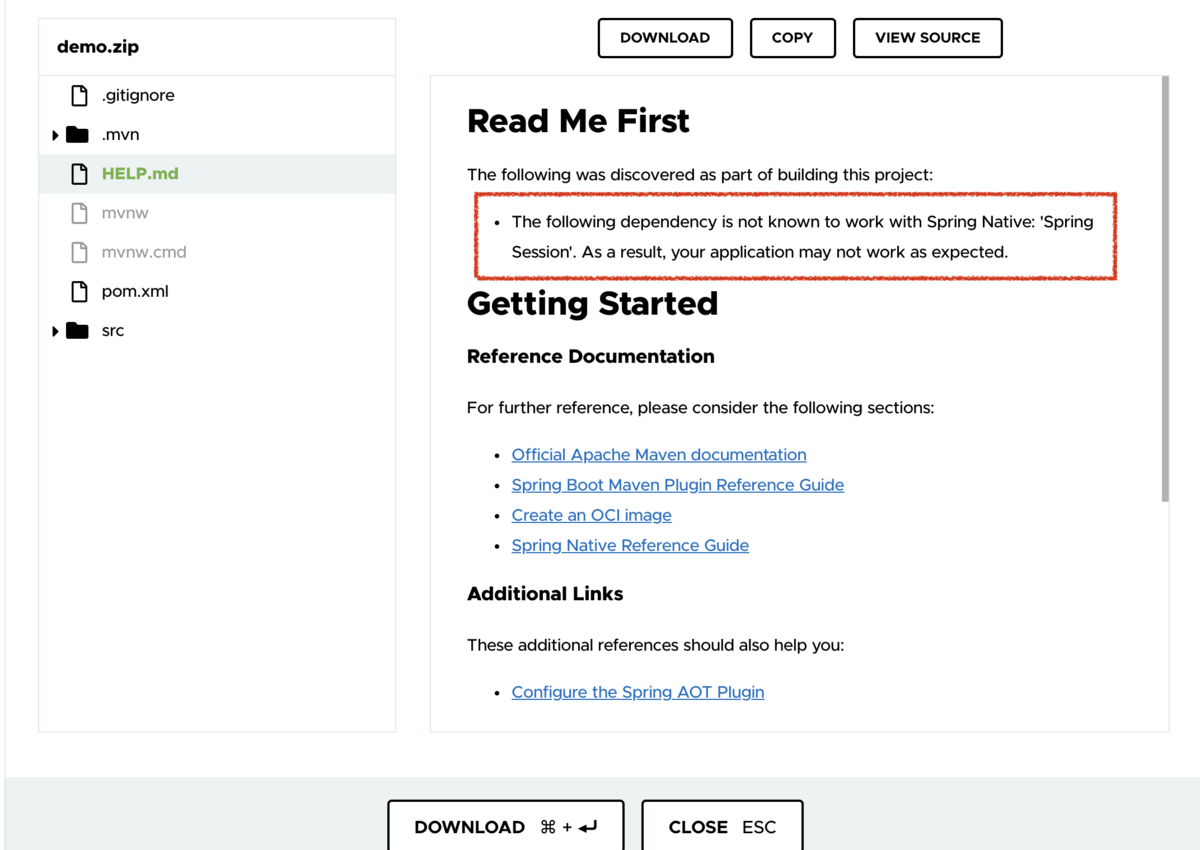
また、Spring Nativeの動作範囲外のOSSが入っている場合、HELP.mdにサポート範囲外のため予期せぬ動きをする可能性がある、といった注意文が入ります。
Spring Nativeのサポート範囲
Spring NativeはまだBeta版であるゆえにサポートされている範囲が明記されています。
GraalVM 21.0.0、Javaは8か11、Kotlinは1.3以上となっており、Spring Bootは2.4.3がサポート対象となっています。今後、Spring Bootのバージョンと共に上がっていくと謳っています。 Spring Native 0.9.0はSpring Boot 2.4.3に、Spring Native 0.9.1はSpring Boot 2.4.4に、といった具合です。
また、samples配下のプロジェクトをみてもらえればなんとなくわかりますが、以下のSpring Boot, Spring Cloud プロジェクトがサポートされています。(Spring Cloudは2020.0.1をサポート)
- spring-boot-starter-actuator
- WebMvc and WebFlux がサポート対象
- spring-boot-starter-data-elasticsearch
- spring-boot-starter-data-jdbc
- spring-boot-starter-data-jpa
- spring-boot-starter-data-mongodb
- spring-boot-starter-data-neo4j
- spring-boot-starter-data-r2dbc
- spring-boot-starter-data-redis
- spring-boot-starter-jdbc
- spring-boot-starter-logging
- spring-boot-starter-mail
- spring-boot-starter-thymeleaf
- spring-boot-starter-rsocket
- spring-boot-starter-validation
- spring-boot-starter-security
- WebMvc and WebFlux でのログイン、HTTP Basic認証、 OAuth 2.0をサポート。RSocketはサポート対象外。
- spring-boot-starter-oauth2-resource-server: WebMvc and WebFlux are supported.
- spring-boot-starter-oauth2-client
- WebMvc and WebFlux がサポート対象
- spring-boot-starter-webflux
- Nettyのみサポート
- spring-boot-starter-web
- spring-boot-starter-websocket
- com.wavefront:wavefront-spring-boot-starter
- spring-cloud-starter-bootstrap
- spring-cloud-starter-config
- spring-cloud-config-client
- spring-cloud-config-server
- spring-cloud-starter-netflix-eureka-client (Java 11 のみ)
- spring-cloud-function-web
- spring-cloud-function-adapter-aws
- spring-cloud-starter-function-webflux
また、以下についてもサポートされているようです。
- Spring Kafka
- GRPC
- H2 database
- Mysql JDBC driver
- PostgreSQL JDBC driver
動作確認
今回は Spring Native リポジトリのsamplesの中からwebflux-nettyを利用して動かしてみます。
とはいってもREADME.mdに記載されている通り、Docker Daemonを立ち上げて コマンドを打つだけ。
$ mvn spring-boot:build-image

親のpom.xmlにbuildimageの設定がされているため、以前みたようにPaketo BuildpackをベースにしたDocker Imageが作成されています。
$ docker-compose up

0.036秒で起動。やはり早い。早いは正義。アプリケーションもきちんと動いていそうです。
まとめ
ということでSpring Native Beta版の簡単な紹介をしてみました。まだBeta版でありすぐプロダクションで使えるような状態ではないかもしれないですが、これからの流れとしてきっとNative Imageは主流になっていくと思うので(というかなってほしい)、積極的に使っていき発展を見守りたいですね。
Spring Boot2.3でCloud Native Buildpacksを利用したDocker Imageを作成する
概要
Spring Boot2.3から導入されたCloud Native Buildpackを使ったDocker Image作成の作成について掘り下げていきます。
Github Repository
Spring Boot 2.3でのDocker Image作成機能
Spring Boot 2.3ではDocker Daemonが起動していれば1コマンドでCloud Native Buildpackを利用したOCI標準なDocker Imageを作成することができるようになりました。 これによりDockerfileを書かずに誰でも簡単にDocker Imageを作成することができます。
# build dockage image $ mvn spring-boot:build-image # execute application $ docker run -it -p 8080:8080 build-image:0.0.1-SNAPSHOT ### 8080ポートでアプリケーションが立ち上がる
とはいえ、このプラグインがやっているのはDockerfileを開発者の代わりに作ってくれている、ということではありません。Cloud Native Buildpackを利用したOCI標準なDocker Imageを作成してくれています。
そして、spring-boot-maven-pluginではデフォルトでPaketo BuildpacksというCloud Foundry発のOSSを利用しています。
Cloud Native Buildpacks
Cloud Native BuildpacksはCNCFのSandboxプロジェクトであり、HerokuやPivotalで利用されていたBuildpackの技術を統合させたものになります。 これにより、今までは特定のPaaSプラットフォームでしか利用できなかった技術がDocker Image同等のものとして色んなクラウド上で扱えるようになりました。

Cloud Native Buildpackの構成
Cloud Native BuildpackのImageはBuildpack, Lifecycle, Stackによって作られたBuilder Imageにて、実際に動かすアプリケーションをbuildすることによって作られます。

各コンポーネントの役割は以下のとおりです。
Buildpack
アプリケーションを動かすためのビルド、あるいはそのための環境構築などを担うコンポーネントです。 Buildpackの実行はdetect/buildの2つのフェーズから構成されます。Buildpackは選ばれたら必ず実行されるというわけではなく、detectフェーズでこのbuildpackを実行すべきかどうか判断し、detectの条件を全て満たしたらbuild, そうじゃなかったらこのBuildpackはスキップ、といった形で処理が走ります。
detectフェーズではこのBuildpackをbuildするために必要なファイルがあるかどうかなどをチェックします。NPM buildpackであればpackage.jsonを探す、といった具合です。
buildフェーズでは文字通りソースコードのビルドなどを行います。たいていのBuilder Imageは複数のBuildpackを組み合わせて実行されるため、1つのBuildpackで全てを実行するわけではありません。中には依存関係を解決するためのBuildpackなどもあります。
Lifecycle
Buildpackより一段上の階層に立って、Buildpackの実行管理や最終的に作成するDocker Imageの構築を担います。こちらもフェーズが分かれており、detection/analysis/build/exportという4つの手順が存在します。
detectionではbuildフェーズで利用するbuildpackの選定を行います。analysisではメタデータやレイヤーキャッシュを展開するといった処理を行います。 buildでは実際にソースコードから実行可能なartifactへのビルド処理を行い、最後のexportでDocker Imageへの書き出しを行います。
ちょっと気になったのはdetectionフェーズ。Buildpackにもdetectフェーズが存在するので、個々のBuildpackのdetectに任せてもいいように見えます。Buildpack同士での競合などを防ぐなどの役割があるのでしょうか。
Stack
Buildpack, LifecycleのベースとなるOS Imageを表します。
build imageとrun imageの2種類が用意されている通り、ビルド時と実行時でStackの違うImageが利用されています。Ubuntuベースのイメージなどが多いようです。
Paketo Buildpacks
Paketo BuildpacksはCloud Native Buildpacksの規格に沿ったGo製のOSSです。 各種言語をサポートしており、 Cloud Foundryプロジェクトによって作成されています。
実は、今回紹介している spring-boot:build-imageでは、デフォルトのBuilder ImageにPaketo Buildpacksが使われています。(github)

mvn spring-boot:build-imageは何をしているか
さて、改めてmvn spring-boot:build-image 実行時のログを追ってみます。(興味があるのはbuild-imageの部分なので、そこまでのログは少し省略しています)
<@buildImage>-<⎇ master>-> mvn spring-boot:build-image [INFO] Scanning for projects... [INFO] [INFO] ----------------------< dev.yoghurt:build-image >----------------------- [INFO] Building build-image 0.0.1-SNAPSHOT [INFO] --------------------------------[ jar ]--------------------------------- [INFO] [INFO] >>> spring-boot-maven-plugin:2.3.3.RELEASE:build-image (default-cli) > package @ build-image >>> [INFO] ... [INFO] [INFO] --- maven-surefire-plugin:2.22.2:test (default-test) @ build-image --- ... ... [INFO] --- spring-boot-maven-plugin:2.3.3.RELEASE:build-image (default-cli) @ build-image --- [INFO] Building image 'docker.io/library/build-image:0.0.1-SNAPSHOT' [INFO] [INFO] > Pulling builder image 'gcr.io/paketo-buildpacks/builder:base-platform-api-0.3' 0% [INFO] > Pulling builder image 'gcr.io/paketo-buildpacks/builder:base-platform-api-0.3' 100% [INFO] > Pulled builder image 'gcr.io/paketo-buildpacks/builder@sha256:3284c03370a31854fee91c71c037081406ce2d69b5b7e3926a6a9e134f7e0d2f' [INFO] > Pulling run image 'docker.io/paketobuildpacks/run:base-cnb' 0% [INFO] > Pulling run image 'docker.io/paketobuildpacks/run:base-cnb' 24% [INFO] > Pulling run image 'docker.io/paketobuildpacks/run:base-cnb' 100% [INFO] > Pulled run image 'paketobuildpacks/run@sha256:86edad85f315d115ca1784c4a72abbde0b12650c9b993be95fd4a7bcc8900f70' [INFO] > Executing lifecycle version v0.9.1 [INFO] > Using build cache volume 'pack-cache-d1d004e77dd4.build' [INFO] [INFO] > Running creator [INFO] [creator] ===> DETECTING [INFO] [creator] 5 of 17 buildpacks participating [INFO] [creator] paketo-buildpacks/bellsoft-liberica 3.2.0 [INFO] [creator] paketo-buildpacks/executable-jar 3.1.0 [INFO] [creator] paketo-buildpacks/apache-tomcat 2.2.0 [INFO] [creator] paketo-buildpacks/dist-zip 2.2.0 [INFO] [creator] paketo-buildpacks/spring-boot 3.2.0 [INFO] [creator] ===> ANALYZING [INFO] [creator] Restoring metadata for "paketo-buildpacks/bellsoft-liberica:helper" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/bellsoft-liberica:java-security-properties" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/bellsoft-liberica:jre" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/bellsoft-liberica:jvmkill" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/executable-jar:class-path" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/spring-boot:helper" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/spring-boot:spring-cloud-bindings" from app image [INFO] [creator] Restoring metadata for "paketo-buildpacks/spring-boot:web-application-type" from app image [INFO] [creator] ===> RESTORING [INFO] [creator] ===> BUILDING [INFO] [creator] [INFO] [creator] Paketo BellSoft Liberica Buildpack 3.2.0 [INFO] [creator] https://github.com/paketo-buildpacks/bellsoft-liberica [INFO] [creator] Build Configuration: [INFO] [creator] $BP_JVM_VERSION 11.* the Java version [INFO] [creator] Launch Configuration: [INFO] [creator] $BPL_JVM_HEAD_ROOM 0 the headroom in memory calculation [INFO] [creator] $BPL_JVM_LOADED_CLASS_COUNT 35% of classes the number of loaded classes in memory calculation [INFO] [creator] $BPL_JVM_THREAD_COUNT 250 the number of threads in memory calculation [INFO] [creator] $JAVA_TOOL_OPTIONS the JVM launch flags [INFO] [creator] BellSoft Liberica JRE 11.0.8: Reusing cached layer [INFO] [creator] Launch Helper: Reusing cached layer [INFO] [creator] JVMKill Agent 1.16.0: Reusing cached layer [INFO] [creator] Java Security Properties: Reusing cached layer [INFO] [creator] [INFO] [creator] Paketo Executable JAR Buildpack 3.1.0 [INFO] [creator] https://github.com/paketo-buildpacks/executable-jar [INFO] [creator] Process types: [INFO] [creator] executable-jar: java org.springframework.boot.loader.JarLauncher [INFO] [creator] task: java org.springframework.boot.loader.JarLauncher [INFO] [creator] web: java org.springframework.boot.loader.JarLauncher [INFO] [creator] [INFO] [creator] Paketo Spring Boot Buildpack 3.2.0 [INFO] [creator] https://github.com/paketo-buildpacks/spring-boot [INFO] [creator] Launch Helper: Reusing cached layer [INFO] [creator] Web Application Type: Reusing cached layer [INFO] [creator] Spring Cloud Bindings 1.6.0: Reusing cached layer [INFO] [creator] Image labels: [INFO] [creator] org.opencontainers.image.title [INFO] [creator] org.opencontainers.image.version [INFO] [creator] org.springframework.boot.spring-configuration-metadata.json [INFO] [creator] org.springframework.boot.version [INFO] [creator] ===> EXPORTING [INFO] [creator] Reusing layer 'paketo-buildpacks/bellsoft-liberica:helper' [INFO] [creator] Reusing layer 'paketo-buildpacks/bellsoft-liberica:java-security-properties' [INFO] [creator] Reusing layer 'paketo-buildpacks/bellsoft-liberica:jre' [INFO] [creator] Reusing layer 'paketo-buildpacks/bellsoft-liberica:jvmkill' [INFO] [creator] Reusing layer 'paketo-buildpacks/executable-jar:class-path' [INFO] [creator] Reusing layer 'paketo-buildpacks/spring-boot:helper' [INFO] [creator] Reusing layer 'paketo-buildpacks/spring-boot:spring-cloud-bindings' [INFO] [creator] Reusing layer 'paketo-buildpacks/spring-boot:web-application-type' [INFO] [creator] Adding 1/1 app layer(s) [INFO] [creator] Reusing layer 'launcher' [INFO] [creator] Adding layer 'config' [INFO] [creator] Adding label 'io.buildpacks.lifecycle.metadata' [INFO] [creator] Adding label 'io.buildpacks.build.metadata' [INFO] [creator] Adding label 'io.buildpacks.project.metadata' [INFO] [creator] Adding label 'org.opencontainers.image.title' [INFO] [creator] Adding label 'org.opencontainers.image.version' [INFO] [creator] Adding label 'org.springframework.boot.spring-configuration-metadata.json' [INFO] [creator] Adding label 'org.springframework.boot.version' [INFO] [creator] *** Images (45ec6ed55538): [INFO] [creator] docker.io/library/build-image:0.0.1-SNAPSHOT [INFO] [INFO] Successfully built image 'docker.io/library/build-image:0.0.1-SNAPSHOT' [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------
さきほども記載したとおり、Paketo BuildpacksのBuilderが使われていることがわかります。
また、Executing lifecycle以降を見ると、 ===> DETECTING....===> BUILDINGとLifecycleの各フェーズが順に実行されていることがわかります。
DETECTINGフェーズでは、5つのBuildpackがヒットしていることがわかります。
[INFO] [creator] 5 of 17 buildpacks participating [INFO] [creator] paketo-buildpacks/bellsoft-liberica 3.2.0 [INFO] [creator] paketo-buildpacks/executable-jar 3.1.0 [INFO] [creator] paketo-buildpacks/apache-tomcat 2.2.0 [INFO] [creator] paketo-buildpacks/dist-zip 2.2.0 [INFO] [creator] paketo-buildpacks/spring-boot 3.2.0
また、そのうち3つのBuildpackが、(おそらく)Buildpackのdetectで成功しBUILDINGフェーズで実行されています。
[INFO] [creator] ===> BUILDING [INFO] [creator] [INFO] [creator] Paketo BellSoft Liberica Buildpack 3.2.0 ... [INFO] [creator] Paketo Executable JAR Buildpack 3.1.0 ... [INFO] [creator] Paketo Spring Boot Buildpack 3.2.0
それぞれのBuildpackが何をしているか、各BuildpackのGithubリポジトリから確認していきます。
Paketo BellSoft Liberica Buildpack
Paketo BellSoft Liberica Buildpackは名前の通り Liberica JDKのBuildpackになります。このBuildpackは他のBuildpackがjreまたはjdkを利用するときに実行されます。
JDKが必要な場面(主にbuilder image)では以下が提供されます。
build,cacheとマークされているlayerへのJDK追加- build layerへの
JAVA_HOME設定 - build layerへの
JDK_HOME設定
また、JREが必要な場面(主にrun image)では以下が提供されます。
- JREの追加
JAVA_HOMEの追加-XX:ActiveProcessorCount(プロセッサーカウントの指定)設定$MALLOC_ARENA_MAX設定- local DNSが有効な場合にJVM DNSキャッシュを無効化
metadata.buildがtrueの場合にレイヤーにbuild,cacheマークを付けるmetadata.launchがtrueの場合にlaunchマークを付けるlaunchが付いたlayerにjvmkillを追加launchが付いたlayerにMemory Calculatorを追加
JDK, JREのインストールやクラウド環境向けの環境変数の設定、jvmkillやmemory calculatorなどの追加が行われています。
jvmkillやmemory calculatorは元々Cloud Foundryのプロダクトでしたが、途中でPaketo側に取り込まれたようです。実際のコードは paketo-buildpacks/libjvmにあります。
Paketo Executable JAR Buildpack
Paketo Executable JAR Buildpackは<アプリケーションルート>/META-INF/MANIFEST.MFが Main-classを含むときに実行されるBuildpackです。このBuildpackでは以下が実行されます。
- JREのインストールをリクエスト
- <アプリケーションルート>をクラスパスに追加
<アプリケーションルート>/META-INF/MANIFEST.MFがクラスパスにある場合にentries(おそらくMain class?)をクラスパスに追加executable-jar,task,webのProcess Typeの指定
最後の記述について、実際に作成したイメージに対して pack inspect-imageを実行し中身を確認するとProcess Tyeが3つ指定されているのがわかります。
Process TypeはDockerのEntryPointのような位置づけのもののようです。
Processes: TYPE SHELL COMMAND ARGS web (default) bash java org.springframework.boot.loader.JarLauncher executable-jar bash java org.springframework.boot.loader.JarLauncher task bash java org.springframework.boot.loader.JarLauncher
Paketo Spring Boot Buildpack
Paketo Spring Boot Buildpackは、<アプリケーションルート>/META-INF/MANIFEST.MFにSpring-Boot-Versionの指定がある場合に実行されます。以下が実行されます。
org.springframework.boot.version,org.springframework.boot.spring-configuration-metadata.json,org.opencontainers.image.title,org.opencontainers.image.versionをImageラベルに追加- Mavenの依存関係を取得
- Spring Cloud Bindingsの追加
<アプリケーションルート>/META-INF/dataflow-configuration-metadata.propertieが存在する場合に、org.springframework.cloud.dataflow.spring-configuration-metadata.jsonをImageラベルに追加。<アプリケーションルート>/META-INF/MANIFEST.MFにSpring-Boot-Layers-Indexが存在する場合に定義されたアプリケーションレイヤーを追加。- Reactiveアプリケーションの場合に
$BPL_JVM_THREAD_COUNT50を設定
Spring Boot周りの設定が盛りだくさんです。リアクティブ向けの設定も行ってくれるのはありがたいですね。
Docker ImageのExport
Lifecycleの最後のフェーズでは、paketo-buildpacksの各種レイヤーがDocker Imageに追加され、labelの設定などが行われています。 このように、コマンド1つで様々な設定を盛り込んだDocker Imageが作成されているのがわかりました。
===> EXPORTING
Reusing layer 'paketo-buildpacks/bellsoft-liberica:helper'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:java-security-properties'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:jre'
Reusing layer 'paketo-buildpacks/bellsoft-liberica:jvmkill'
Reusing layer 'paketo-buildpacks/executable-jar:class-path'
Reusing layer 'paketo-buildpacks/spring-boot:helper'
Reusing layer 'paketo-buildpacks/spring-boot:spring-cloud-bindings'
Reusing layer 'paketo-buildpacks/spring-boot:web-application-type'
Adding 1/1 app layer(s)
Reusing layer 'launcher'
Adding layer 'config'
Adding label 'io.buildpacks.lifecycle.metadata'
Adding label 'io.buildpacks.build.metadata'
Adding label 'io.buildpacks.project.metadata'
Adding label 'org.opencontainers.image.title'
Adding label 'org.opencontainers.image.version'
Adding label 'org.springframework.boot.spring-configuration-metadata.json'
Adding label 'org.springframework.boot.version'
*** Images (45ec6ed55538):
docker.io/library/build-image:0.0.1-SNAPSHOT
まとめ
mvn spring-boot:build-imageコマンドで作成されるImageはPaketo Buildpacksを利用したOCI標準のImageとなっており、様々な設定が自動で行われているのを調べることができました。
個人的に嬉しいのはやはりjvmkillやMemory Calculatorで、これによりOutOfMemory時のJavaプロセスKillやメモリ設定などをやってくれるので、アプリケーション開発者はいっそうソースコードだけに集中することができるようになります。カスタマイズをしたければ自分でbuilder imageを作成して設定を追加することもできますが、このままでも十分プロダクション環境で利用できそうです。
今回初めてCloud Native Buldpacksについて色々調べてみましたが、一つ一つの設定細かく理解仕切ることができなかったりわからない概念がまだまだ残っていたりします。Spring Bootをクラウド上で簡単に動かせるという方向性は大歓迎ですし、実際に動いている基盤は理解していきたいので引き続き色々調べてみようと思います。
RestTemplateをカスタマイズしてHTTPS通信の際にプロキシサーバに認証ヘッダを詰める
やりたいこと
クライアント(Spring Boot)からRestTemplateを用いてサーバへHTTPSのAPI呼び出しを行う、ただし間にプロキシサーバを挟んでおりそのプロキシサーバは認証用のHTTPヘッダが必要、という状況でプロキシサーバの認証を通しつつクライアントサーバ間でHTTPS通信を実現したい、というのが本稿のお題になります。

課題
通常、HTTPSでの通信を行う場合、間にあるプロキシサーバは中身を見ることが出来ないためCONNECTメソッドのリクエストを用いて通信のトンネル化を行います。しかし、プロキシサーバに認証がかかっている場合、CONNECTリクエストに認証用のヘッダを詰めてあげないといけません。そして、RestTemplateで普通にプロキシサーバの設定をしてHTTPS通信をする場合、CONNECTリクエストには本体のリクエスト作成時に詰めた認証ヘッダは付与されません。
// こういう感じだとうまく行かない fun call() { var restTemplate = RestTemplateBuilder().build() val proxyHost = "proxy" val proxyPort = 8888 val address = InetSocketAddress(proxyHost, proxyPort) // プロキシ設定 var requestFactory = SimpleClientHttpRequestFactory() val proxy = Proxy(Proxy.Type.HTTP, address) requestFactory.setProxy(proxy) restTemplate.requestFactory = requestFactory // ここで認証ヘッダを詰めてもCONNECTリクエストには反映されない var headers = HttpHeaders() headers.add("X-AUTH", "authValue") val requestEntity = RequestEntity<Request>(Request(), headers, HttpMethod.GET, URI("https://server")) restTemplate.exchange(requestEntity, Response::class.java) }
実際に上記のようなリクエストを実行してWiresharkでキャプチャしてみると、CONNECTリクエストにはX-AUTHヘッダが含まれていないことがわかります。

CONNECTでも認証ヘッダを詰める
ということでRestTemplateをカスタマイズしCONNECTリクエストに認証ヘッダが詰められるようカスタマイズをします。
先に実装(手段)を書き、その後に中身の仕組みについて解説します。
RestTemplateのカスタマイズ
dependencyにapacheのhttpclientを追加します。
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.12</version> </dependency>
そして、RestTemplateをカスタマイズするために以下の2つのクラスを用意します。
- HttpClientBuilderを拡張したクラス
- ClientHttpRequestFactoryを生成するビルダークラス
HttpClientBuilderを拡張したクラス
これが今回の肝になります。HttpClientBuilderのcreateMainExecメソッドをオーバーライドしたクラスを作成します。
import org.apache.http.ConnectionReuseStrategy import org.apache.http.HttpRequest import org.apache.http.HttpRequestInterceptor import org.apache.http.client.AuthenticationStrategy import org.apache.http.client.UserTokenHandler import org.apache.http.conn.ConnectionKeepAliveStrategy import org.apache.http.conn.HttpClientConnectionManager import org.apache.http.impl.client.HttpClientBuilder import org.apache.http.impl.execchain.ClientExecChain import org.apache.http.protocol.HttpProcessor import org.apache.http.protocol.HttpRequestExecutor import org.apache.http.protocol.ImmutableHttpProcessor import org.apache.http.protocol.RequestTargetHost class HeaderCustomizeHttpClientBuilder : HttpClientBuilder() { companion object { fun create(): HttpClientBuilder { return HeaderCustomizeHttpClientBuilder() } } override fun createMainExec(requestExec: HttpRequestExecutor?, connManager: HttpClientConnectionManager?, reuseStrategy: ConnectionReuseStrategy?, keepAliveStrategy: ConnectionKeepAliveStrategy?, proxyHttpProcessor: HttpProcessor?, targetAuthStrategy: AuthenticationStrategy?, proxyAuthStrategy: AuthenticationStrategy?, userTokenHandler: UserTokenHandler?): ClientExecChain { val headerCustomizeHttpProcessor = ImmutableHttpProcessor( RequestTargetHost(), HttpRequestInterceptor { request: HttpRequest, _ -> request.addHeader("X-AUTH", "authValue") } ) return super.createMainExec(requestExec, connManager, reuseStrategy, keepAliveStrategy, /* customized processor*/ headerCustomizeHttpProcessor, targetAuthStrategy, proxyAuthStrategy, userTokenHandler) } }
headerCustomizeHttpProcessorを生成しているところに注目してください。この第2引数に渡している
HttpRequestInterceptor { request: HttpRequest, _ -> request.addHeader("X-AUTH", "authValue") }
がリクエストにヘッダを詰める処理となります。
そして、このheaderCustomizeHttpProcessorをsuper.createMainExecのproxyHttpProcessorとして渡しています。
ClientHttpRequestFactoryを生成するビルダー
次に、上記にビルダーを受け取ってRequestFactoryを返すビルダーを実装します。
import org.apache.http.HttpHost import org.springframework.http.client.ClientHttpRequestFactory import org.springframework.http.client.HttpComponentsClientHttpRequestFactory class ProxyClientHttpRequestFactoryBuilder(private val httpHost: HttpHost) { fun build(): ClientHttpRequestFactory { var httpClientBuilder = HeaderCustomizeHttpClientBuilder.create() httpClientBuilder.setProxy(httpHost) return HttpComponentsClientHttpRequestFactory(httpClientBuilder.build()) } }
ここでは先程のHeaderCustomizeHttpClientBuilderから作成したHttpClientBuilderにプロキシをセットしてからHttpClientを.build()し、HttpComponentsClientHttpRequestFactoryクラスに渡しています。
RestTemplateのカスタマイズ
それでは上記の2つのクラスをもとに最初の例ではRestTemplateBuilder().build()するだけだったRestTemplateをカスタマイズします。
fun callCustomized() { val proxyHost = "proxy" val proxyPort = 8888 val requestFactoryBuilder = ProxyClientHttpRequestFactoryBuilder(HttpHost(proxyHost, proxyPort)) var restTemplate = RestTemplateBuilder() .requestFactory{ requestFactoryBuilder.build() } .build() var headers = HttpHeaders() val requestEntity = RequestEntity<Request>(Request(), headers, HttpMethod.GET, URI("https://server")) restTemplate.exchange(requestEntity, Response::class.java) }
このようにしてあげると、リクエストをする際にHeaderCustomizeHttpClientBuilderにてセットされたHttpProcessorが利用され、CONNECTリクエストに認証用のヘッダを詰めることができるようになります。
実際にWiresharkでも、X-AUTHヘッダが埋められていることを確認できました。

仕組み
さて、上記で課題は解決出来たのですが最初は正直「なんで上手くいくの?」状態でした。自分たちで用意したHttpProcessorが使われているであろうことはわかったけど内部の繋がりが理解できていません。
解説するのは難しいですが、中の仕組みを紐解いていきます。(ここからはライブラリ内の話になるのでソースコードはJavaになります)
RestTemplateにおけるRequestFactoryの使われ方
まずは今回差し替えたRequestFactoryについて。これはどのようなものでしょうか。 TERASOLUNAのRestTemplateの解説ページがわかりやすく記載されているので引用します。(Overviewに記載されている図もとてもわかりやすいです)
RestTemplateは、サーバとの通信処理を以下の3つのインタフェースの実装クラスに委譲することで実現している。
- org.springframework.http.client.ClientHttpRequestFactory
- org.springframework.http.client.ClientHttpRequest
- org.springframework.http.client.ClientHttpResponse
この3つのインタフェースのうち、開発者が意識するのはClientHttpRequestFactoryである。 ClientHttpRequestFactoryは、サーバとの通信処理を行うクラス(ClientHttpRequestと ClientHttpResponseインタフェースの実装クラス)を解決する役割を担っている。
実際にClientHttpRequestFactoryインターフェースを見てみると以下のようにClientHttpRequestを生成するメソッドが用意されています。
@FunctionalInterface public interface ClientHttpRequestFactory { ClientHttpRequest createRequest(URI var1, HttpMethod var2) throws IOException; }
設定がない場合、この実装クラスはorg.springframework.http.client.SimpleClientHttpRequestFactoryが選ばれます。
一方で今回利用したHttpComponentsClientHttpRequestFactoryクラスのcreateRequestを見てみましょう。
public ClientHttpRequest createRequest(URI uri, HttpMethod httpMethod) throws IOException { HttpClient client = this.getHttpClient(); HttpUriRequest httpRequest = this.createHttpUriRequest(httpMethod, uri); this.postProcessHttpRequest(httpRequest); HttpContext context = this.createHttpContext(httpMethod, uri); if (context == null) { context = HttpClientContext.create(); } if (((HttpContext)context).getAttribute("http.request-config") == null) { RequestConfig config = null; if (httpRequest instanceof Configurable) { config = ((Configurable)httpRequest).getConfig(); } if (config == null) { config = this.createRequestConfig(client); } if (config != null) { ((HttpContext)context).setAttribute("http.request-config", config); } } return (ClientHttpRequest)(this.bufferRequestBody ? new HttpComponentsClientHttpRequest(client, httpRequest, (HttpContext)context) : new HttpComponentsStreamingClientHttpRequest(client, httpRequest, (HttpContext)context)); }
client = this.getHttpClient();はHttpComponentsClientHttpRequestFactoryのコンストラクタで渡されたHttpClientで、今回作成したHttpClientBuilderから作られたものが渡ってきています。
そして中では色々やっていますが最終的にHttpComponentsClientHttpRequestのインスタンスにclientごと渡しています。
HttpComponentsClientHttpRequestを見てみましょう。
final class HttpComponentsClientHttpRequest extends AbstractBufferingClientHttpRequest { private final HttpClient httpClient; private final HttpUriRequest httpRequest; private final HttpContext httpContext; HttpComponentsClientHttpRequest(HttpClient client, HttpUriRequest request, HttpContext context) { this.httpClient = client; this.httpRequest = request; this.httpContext = context; } // -------中略------- // -------中略------- protected ClientHttpResponse executeInternal(HttpHeaders headers, byte[] bufferedOutput) throws IOException { addHeaders(this.httpRequest, headers); if (this.httpRequest instanceof HttpEntityEnclosingRequest) { HttpEntityEnclosingRequest entityEnclosingRequest = (HttpEntityEnclosingRequest)this.httpRequest; HttpEntity requestEntity = new ByteArrayEntity(bufferedOutput); entityEnclosingRequest.setEntity(requestEntity); } HttpResponse httpResponse = this.httpClient.execute(this.httpRequest, this.httpContext); return new HttpComponentsClientHttpResponse(httpResponse); } }
executeInternal()メソッドの内部でthis.httpClient.execute(this.httpRequest, this.httpContext);されているのがわかります。そのためここで自前で用意したHttpClientのexecuteメソッドが呼ばれていることがわかりました。
また、このexecuteInternal()は親クラスであるAbstractClientHttpRequestにて呼ばれています。
public abstract class AbstractClientHttpRequest implements ClientHttpRequest { // -------中略------- // -------中略------- public final ClientHttpResponse execute() throws IOException { this.assertNotExecuted(); ClientHttpResponse result = this.executeInternal(this.headers); this.executed = true; return result; }
そしてこのexecuteメソッドは何かというと....
public interface ClientHttpRequest extends HttpRequest, HttpOutputMessage { ClientHttpResponse execute() throws IOException; }
ClientHttpRequestのexecute()になります。RestTemplateで実際にリクエストを送信するのはこのメソッドになるので、RequestFactoryを差し替えることで自前のHttpClientが呼ばれていそう、ということがわかります。
createMainExecの呼び出し
HeaderCustomizeHttpClientBuilderクラスではHttpClientBuilder.createMainExec()メソッドをオーバーライドしました。 このcreateMainExec()メソッドは、HttpClientBuilder.build()メソッドの中で登場します。
public class HttpClientBuilder { // -------中略------- // -------中略------- public CloseableHttpClient build() { // -------中略------- // -------中略------- ClientExecChain execChain = createMainExec( requestExecCopy, connManagerCopy, reuseStrategyCopy, keepAliveStrategyCopy, new ImmutableHttpProcessor(new RequestTargetHost(), new RequestUserAgent(userAgentCopy)), targetAuthStrategyCopy, proxyAuthStrategyCopy, userTokenHandlerCopy); // -------中略------- return new InternalHttpClient( execChain, connManagerCopy, routePlannerCopy, cookieSpecRegistryCopy, authSchemeRegistryCopy, defaultCookieStore, defaultCredentialsProvider, defaultRequestConfig != null ? defaultRequestConfig : RequestConfig.DEFAULT, closeablesCopy); }
createMainExec()の第5引数であるproxyHttpProcessorは、HttpClientBulder.build()メソッドの中でnew ImmutableHttpProcessor(new RequestTargetHost(), new RequestUserAgent(userAgentCopy)),インスタンスが渡されています。
今回はここのImmutableHttpProcessorを、引数で渡されたインスタンスを無視して差し替えた形になります。
// 今回差し替えたImmutableHttpProcessor val headerCustomizeHttpProcessor = ImmutableHttpProcessor( RequestTargetHost(), HttpRequestInterceptor { request: HttpRequest, _ -> request.addHeader("X-AUTH", "authValue") } ) return super.createMainExec(requestExec, connManager, reuseStrategy, keepAliveStrategy, /* customized processor*/ headerCustomizeHttpProcessor, targetAuthStrategy, proxyAuthStrategy, userTokenHandler) } }
そして、差し替えたImmutableHttpProcessorを持つClientExecChainはHttpClientBuilder.build()メソッドの最後でInternalHttpClientのインスタンスを生成する際に渡されています。
ImmutableHttpProcessorが実行されるためのMainClientExec.execute()メソッドはこのInternalHttpClientのdoExecute()メソッド内で呼ばれます。(ImmutableHttpProcessorが実行されるところは後述します。)
class InternalHttpClient extends CloseableHttpClient implements Configurable { // -------中略------- @Override protected CloseableHttpResponse doExecute( final HttpHost target, final HttpRequest request, final HttpContext context) throws IOException, ClientProtocolException { // -------中略------- return this.execChain.execute(route, wrapper, localcontext, execAware); } }
そして(長い....)このInternalHttpClientのdoExecute()がどこで呼ばれるかというと...
public abstract class CloseableHttpClient implements HttpClient, Closeable { private final Log log = LogFactory.getLog(getClass()); protected abstract CloseableHttpResponse doExecute(HttpHost target, HttpRequest request, HttpContext context) throws IOException, ClientProtocolException; /** * {@inheritDoc} */ @Override public CloseableHttpResponse execute( final HttpHost target, final HttpRequest request, final HttpContext context) throws IOException, ClientProtocolException { return doExecute(target, request, context); } // -------中略------- }
CloseableHttpClientのexecute()メソッド、すなわちHttpClientのexecute()メソッドになります。
HttpClientのexecute()は、HttpComponentsClientHttpRequestのexecuteInternal()で呼ばれていました!
(再掲)
final class HttpComponentsClientHttpRequest extends AbstractBufferingClientHttpRequest { // -------中略------- protected ClientHttpResponse executeInternal(HttpHeaders headers, byte[] bufferedOutput) throws IOException { addHeaders(this.httpRequest, headers); // -------中略------- HttpResponse httpResponse = this.httpClient.execute(this.httpRequest, this.httpContext); return new HttpComponentsClientHttpResponse(httpResponse); } }
ようやく繋がりました。すなわち、今回作成したHeaderCustomizeHttpClientBuilder,ProxyClientHttpRequestFactoryBuilderの2つはRestTemplateで呼ばれるHttpClient(実態はInternalHttpClient)の、execte()内のdoExecute()で呼出されるClientExecChain.execute()を拡張していることになります。書いているだけで舌を噛みそうですね。
さて、それでは最後にMainClientExecでImmutableHttpProcessorが処理されている場所を見ていきます。
CONNECTリクエストが生成される場所
MainClientExec.execute()の中を紐解いていきます。メソッド内のコネクションを確立するメソッドestablishRoute()に着目します。
public class MainClientExec implements ClientExecChain { // -------中略------- @Override public CloseableHttpResponse execute( final HttpRoute route, final HttpRequestWrapper request, final HttpClientContext context, final HttpExecutionAware execAware) throws IOException, HttpException { // -------中略------- if (!managedConn.isOpen()) { this.log.debug("Opening connection " + route); try { establishRoute(proxyAuthState, managedConn, route, request, context); } catch (final TunnelRefusedException ex) { // -------中略------- }
establishRoute()内では、まさに最初に説明したProxyサーバを挟んだ場合にHTTPS通信時の動きが実装されています。
void establishRoute( final AuthState proxyAuthState, final HttpClientConnection managedConn, final HttpRoute route, final HttpRequest request, final HttpClientContext context) throws HttpException, IOException { final RequestConfig config = context.getRequestConfig(); final int timeout = config.getConnectTimeout(); final RouteTracker tracker = new RouteTracker(route); int step; do { final HttpRoute fact = tracker.toRoute(); step = this.routeDirector.nextStep(route, fact); switch (step) { case HttpRouteDirector.CONNECT_TARGET: this.connManager.connect( managedConn, route, timeout > 0 ? timeout : 0, context); tracker.connectTarget(route.isSecure()); break; case HttpRouteDirector.CONNECT_PROXY: this.connManager.connect( managedConn, route, timeout > 0 ? timeout : 0, context); final HttpHost proxy = route.getProxyHost(); tracker.connectProxy(proxy, route.isSecure() && !route.isTunnelled()); break; case HttpRouteDirector.TUNNEL_TARGET: { final boolean secure = createTunnelToTarget( proxyAuthState, managedConn, route, request, context); this.log.debug("Tunnel to target created."); tracker.tunnelTarget(secure); } break; case HttpRouteDirector.TUNNEL_PROXY: { // The most simple example for this case is a proxy chain // of two proxies, where P1 must be tunnelled to P2. // route: Source -> P1 -> P2 -> Target (3 hops) // fact: Source -> P1 -> Target (2 hops) final int hop = fact.getHopCount()-1; // the hop to establish final boolean secure = createTunnelToProxy(route, hop, context); this.log.debug("Tunnel to proxy created."); tracker.tunnelProxy(route.getHopTarget(hop), secure); } break; case HttpRouteDirector.LAYER_PROTOCOL: this.connManager.upgrade(managedConn, route, context); tracker.layerProtocol(route.isSecure()); break; case HttpRouteDirector.UNREACHABLE: throw new HttpException("Unable to establish route: " + "planned = " + route + "; current = " + fact); case HttpRouteDirector.COMPLETE: this.connManager.routeComplete(managedConn, route, context); break; default: throw new IllegalStateException("Unknown step indicator " + step + " from RouteDirector."); } } while (step > HttpRouteDirector.COMPLETE); }
受け取ったHttpRoute(中身は {tls} http://proxy:8888 -> https://server:443というような表現になっています)をもとに、RouteDirector.nextStepでもらった処理をdo~whileブロック内で実行していきます。
最初はCONNECT_PROXY、プロキシサーバとのコネクション確立が実行されます。その次にトンネル化の処理TUNNEL_TARGETが実行されます。このTUNNEL_TARGETで呼び出されているcreateTunnelToTarget()メソッドがトンネル化、すなわちCONNECTリクエストを投げている部分になります。
/** * Creates a tunnel to the target server. * The connection must be established to the (last) proxy. * A CONNECT request for tunnelling through the proxy will * be created and sent, the response received and checked. * This method does <i>not</i> update the connection with * information about the tunnel, that is left to the caller. */ private boolean createTunnelToTarget( final AuthState proxyAuthState, final HttpClientConnection managedConn, final HttpRoute route, final HttpRequest request, final HttpClientContext context) throws HttpException, IOException { final RequestConfig config = context.getRequestConfig(); final int timeout = config.getConnectTimeout(); final HttpHost target = route.getTargetHost(); final HttpHost proxy = route.getProxyHost(); HttpResponse response = null; final String authority = target.toHostString(); final HttpRequest connect = new BasicHttpRequest("CONNECT", authority, request.getProtocolVersion()); this.requestExecutor.preProcess(connect, this.proxyHttpProcessor, context); while (response == null) { if (!managedConn.isOpen()) { this.connManager.connect( managedConn, route, timeout > 0 ? timeout : 0, context); } connect.removeHeaders(AUTH.PROXY_AUTH_RESP); this.authenticator.generateAuthResponse(connect, proxyAuthState, context); response = this.requestExecutor.execute(connect, managedConn, context); // ------- 省略-------
この中の2行
final HttpRequest connect = new BasicHttpRequest("CONNECT", authority, request.getProtocolVersion()); this.requestExecutor.preProcess(connect, this.proxyHttpProcessor, context);
の部分でCONNECTリクエストを作成し、requestExecutor.preProcessメソッドにて今回作成したproxyHttpProcessorが渡されています。preProcess内では渡されたproxyHttpProcessor内のHttpRequestInterceptorが順に実行されていき、ようやくここでX-AUTHヘッダがリクエストにセットされます。ここまで来ないとCONNECT用のリクエストインスタンスが作られないため、もとのリクエストでセットされたヘッダはここまで渡ってきません。HttpClientBuilderのcreateMainExecをオーバーライドすることで初めてProxyサーバに送るCONNECTリクエストに独自の実装を行うことができたのです。
まとめ
SpringのRestTemplateを用いて、ProxyサーバへのCONNECTリクエスト作成時に独自の認証ヘッダを挿し込む方法を紹介しました。実際の実現方法だけでなくRestTemplate、HttpClientの中身を見ていくことで今まで意識していなかった内部の動きについても詳しくなった気がします。
また、今回実装したクラスは ↓に上がっています。 github.com
花粉症対策2020
例年の花粉症の症状と今年の症状
花粉症は天敵で、例年どおりならくしゃみが止まらず1日でティッシュ1箱使い切る、頭もボーッとするし薬のせいで仕事に全然集中できない、という有様なのだが、今年は病院にも行かずほとんど症状が出てない(1日数回のくしゃみ程度)ので今年やった花粉症対策を備忘録的に残そうと思う。
今年の花粉症対策
資生堂 イハダアレルスクリーン
体感一番効いている対策NO.1。スプレーをする前とした後では鼻のムズムズ感がぜんぜん違う。シャワーを浴びたり顔を洗ったりすると落ちてしまって鼻がムズムズしてくるのだが、このスプレーをすると治まる気がする。僕の場合外出時はもちろん屋内でもくしゃみが止まらないときはあるので、外に出る出ない関係なく1日1回このスプレーをしている。
甜茶
甜茶は甘い中国のお茶で、いくつか種類があるようだが甜葉懸鈎子(てんようけんこうし)の茶葉を使ったものを飲用している。調べるとインターネット各所で花粉症などのアレルギーに効く、という話は出てくるがあまり科学的な根拠が強いわけでもなさそうなので実態はやや不明。
花粉が飛び始める少し前から飲むといいいとされているので、1月くらいから飲用し始めていた。今回の対策では一番最初から取り組んでいたものになるが、いかんせん長期スパンなので効いている体感はそんなにない。でも普通に美味しいので飲み続けようと思う。
漢方 小青竜湯
アレルギー性鼻炎に効くと知って購入した。1日2回食前または食中に飲んでいるが、たまに飲み忘れてもそんなに症状は変わらない(他でカバーできているという可能性もある)ため、あまり効果は体感できていない。もしかしたら効いてくれているのかもしれないが、ズボラなので飲み忘れがち。薬代が一番高いので、効果があまり無さそうなら来年は止めてみようと思う。
アイボン AL
こちらは目のかゆみ対策。普段はコンタクトなので夜寝る前などにこれをやって目の掃除をしている。なんとなくこれをやり忘れると次の日はいつもより目がかゆい気がするので効いているんだと思う。病院とかでもらう目薬だと点滴したときの刺激で余計に目が痒くなってしまってたりしたのだけれど、この形式であれば目を一定時間ちゃんと目を洗えるので自分には向いている気がした。
コロナウイルスによる外出禁止
もしかしたらこれが一番大きいかもしれない。コロナウイルスの影響で外出自粛のムードが広がっており、僕自身も仕事は在宅、出かける予定もほとんどキャンセルしてしまって家から出ていない。
例年花粉症のときは家から出ていても出ていなくてもくしゃみはひどいので、そこまで関係ないのかもしれないが来年同じような対策をしていてもまた花粉症がひどくなるようだったら、花粉症シーズンにはなるべく家にいるべし、という方針に決められるのでこれはこれで期待したい仮設ではある。
まとめ
例年だと病院で薬をもらうもののあまり効き目がなく、そのわりに眠くなったりボーッとしたりで本当にこの時期は嫌いだったのだが、今年は症状が出てないおかげでかなり気分良く過ごせている。いつもだとお花見に行ってもひたすらくしゃみをしていて涙が止まらなくて花より鼻という悲しい事態になってしまうのだが、この調子なら楽しくお花見ができるかもしれない。今年はコロナウイルスの影響で見送りだけど。
色々一度に試してしまったせいで「これが効いた!」といったものを特定しにくい状況になってしまったのだが、背に腹は代えられないので全部併用している。毎年ちょっとずつ試して自分にあった花粉症対策を見つけていきたい。
Spring Boot(Kotlin)でOAuthを使ってGoogle Calendar APIを叩く
Java(Kotlin)アプリケーションからGoogle CalendarAPIを叩きたい
Spring Bootアプリケーション(Kotlin製)のAPIからGoogle Calendar APIを叩こうとしています。
GoogleのAPIを叩くにはOauthログインが必要で、公式ガイドにはQuick StartがあるにはあるのですがWebアプリ向けではなく、少し工夫が必要でした。
Quick Startに書かれていること
Google Calendar APIにはいくつかの言語でのQuickStartがあり、その中にはJavaもあります。今回はKotlinで書かれたアプリケーションを作っているので厳密には異なるのですが、Javaでの書き方がわかれば問題ありません。
QuickStartにはOauthによる認可を行いカレンダーAPIを叩くまでの流れとサンプルコードが記載されていますが、ここで実装されているのはコマンドラインアプリーケーションであり、Callback用のローカルサーバを立てて認証を行っています。
public class CalendarQuickstart { private static final String APPLICATION_NAME = "Google Calendar API Java Quickstart"; private static final JsonFactory JSON_FACTORY = JacksonFactory.getDefaultInstance(); private static final String TOKENS_DIRECTORY_PATH = "tokens"; // アクセスする権限のスコープ private static final List<String> SCOPES = Collections.singletonList(CalendarScopes.CALENDAR_READONLY); // 認証情報 private static final String CREDENTIALS_FILE_PATH = "/credentials.json"; // 認証情報を取得する処理 private static Credential getCredentials(final NetHttpTransport HTTP_TRANSPORT) throws IOException { // Load client secrets. InputStream in = CalendarQuickstart.class.getResourceAsStream(CREDENTIALS_FILE_PATH); if (in == null) { throw new FileNotFoundException("Resource not found: " + CREDENTIALS_FILE_PATH); } GoogleClientSecrets clientSecrets = GoogleClientSecrets.load(JSON_FACTORY, new InputStreamReader(in)); // 認証に利用するオブジェクトを作成 GoogleAuthorizationCodeFlow flow = new GoogleAuthorizationCodeFlow.Builder( HTTP_TRANSPORT, JSON_FACTORY, clientSecrets, SCOPES) .setDataStoreFactory(new FileDataStoreFactory(new java.io.File(TOKENS_DIRECTORY_PATH))) .setAccessType("offline") .build(); // ローカルサーバを8888ポートで立てる LocalServerReceiver receiver = new LocalServerReceiver.Builder().setPort(8888).build(); return new AuthorizationCodeInstalledApp(flow, receiver).authorize("user"); } // メイン関数 public static void main(String... args) throws IOException, GeneralSecurityException { final NetHttpTransport HTTP_TRANSPORT = GoogleNetHttpTransport.newTrustedTransport(); // カレンダーAPI呼び出し用のオブジェクトを作成。この時点でアクセストークンがないと認証が必要になる。 Calendar service = new Calendar.Builder(HTTP_TRANSPORT, JSON_FACTORY, getCredentials(HTTP_TRANSPORT)) .setApplicationName(APPLICATION_NAME) .build(); // ここから先はGoogle Calendar APIを叩く処理 DateTime now = new DateTime(System.currentTimeMillis()); Events events = service.events().list("primary") .setMaxResults(10) .setTimeMin(now) .setOrderBy("startTime") .setSingleEvents(true) .execute(); List<Event> items = events.getItems(); if (items.isEmpty()) { System.out.println("No upcoming events found."); } else { System.out.println("Upcoming events"); for (Event event : items) { DateTime start = event.getStart().getDateTime(); if (start == null) { start = event.getStart().getDate(); } System.out.printf("%s (%s)\n", event.getSummary(), start); } } } }
ターミナルからキックするとGoogleの認証URLがログに出力され、URLに飛んだ先で認証を行うことでOauthによる認可が行われます。これでAPIを叩くには叩けるんですが、そのままWebアプリに流用するような作りにはなっていません。 QuickStartにも以下の通りしっかり書かれています。
The authorization flow in this example is designed for a command-line application. For information on how to perform authorization in a web application, see Using OAuth 2.0 for Web Server Applications.
Web Server向けの案内はこちらにあるようです。
が Java向けの案内はなく・・・

QuickStartのFurther Readingにはいくつか参考になりそうなリンクがあるんですが、

ここにあるのもQuickStartにあるCommand-Line Application、Android、Google App Engineのみ(というか画像が古い...。Google+って終了してなかったっけ?)
Web Applicationでの叩き方
ということでQuickStatとUsing OAuth 2.0 for Web Server ApplicationsのHTTP版、JavaライブラリのAPI Referenceを参考にしつつWeb Applicationで同じことをやる方法を探りました。
Oauthの流れ
知っている人は読み飛ばしてもらって良いですが、Oauthはざっくりと以下のような流れで認可を行います。

初回ユーザがアクセスしてきた場合、アプリーケーションはGoogleの認証画面へとリダイレクトします。

認証が終わるとあらかじめ設定してあるコールバックURLに飛ばされます。コールバック時にはパラメータとして認証コードがついてきます。
https://oauth2.example.com/auth?code=AUTHORIZATION_CODE
アプリケーションで認証コードを受け取り、それをGoogleのOauth APIへと渡してアクセストークンを取得します。
取得したアクセストークンを利用することでGoogle Calendar APIにアクセスすることができます。
実装
ということでGoogle Calendar APIの利用には以下の処理が必要になります。
認証済みでないユーザが来た際にGoogleの認証ページにリダイレクトする
リダイレクトURLはhttps://accounts.google.com/o/oauth2/v2/auth を叩けば良いようですが、必要なクレデンシャル情報も含めいくつかパラメータが必要になってきます。
ライブラリのリファレンスを漁っているとAuthorizationCodeRequestUrlというそれっぽいクラスが見つかったのでそれを利用して生成することにしました。
https://developers.google.com/api-client-library/java/google-oauth-java-client/reference/1.19.0/com/google/api/client/auth/oauth2/AuthorizationCodeRequestUrl

このクラスのbuildメソッドをKotlinで呼び出してあげます。
val SCOPES = Collections.singletonList(CalendarScopes.CALENDAR_READONLY) // アクセスするスコープを設定 val authUrl = "https://accounts.google.com/o/oauth2/auth" // 認証URL val clientId = "xxxxxxx" // Client ID val callbackUrl = "http://localhost:8080/callback" // コールバック用URL val requestUrl = AuthorizationCodeRequestUrl(authUri, clientId) .setRedirectUri(callbackUrl) .setScopes(SCOPES) .build() // リダイレクト response.sendRedirect(requestUrl)
コールバックのリクエストを受け取ってアクセストークンを取得する
こちらはQuickStartでも利用されていたGoogleAuthorizationCodeFlowのリファレンスに飛んだらヒントがありました。

The web browser will then redirect to the redirect URL with a "code" query parameter which can then be used to request an access token using newTokenRequest(String).
newTokenRequest(String)を呼んであげれば良さそうです。
val request = googleAuthorizationCodeFlow.newTokenRequest(code) .setRedirectUri(googleClientSecrets.details.redirectUris.first()) val response = request.execute() googleCredential.setAccessToken(response.accessToken) return "This is endpoint for google oauth2 callback."
Spring Boot Applicationでの認証処理
最終的なコードは以下のようになりました。
Googleの認証画面へのリダイレクトをインターセプターで実装し、エンドポイントにアノテーションを付与することでControllerの指定したエンドポイントにアクセストークン無しで来た場合、Oauthによる認可が行われます。
@Target(AnnotationTarget.FUNCTION) @Retention(AnnotationRetention.RUNTIME) annotation class GoogleOAuth2 // ControllerにつけるAnnotation
// アクセストークンがない場合に自動でGoogleの認証ページにリダイレクトさせるInterceptor class GoogleOAuth2Interceptor( private val googleClientSecrets: GoogleClientSecrets, // Oauthに利用するプロパティ private val googleCredential: GoogleCredential // Calendar APIに利用するプロパティ ) : HandlerInterceptor { // 利用する権限:カレンダーのREADのみ private val SCOPES = Collections.singletonList(CalendarScopes.CALENDAR_READONLY) private val logger: Logger = LoggerFactory.getLogger(this::class.java) override fun preHandle(request: HttpServletRequest, response: HttpServletResponse, handler: Any): Boolean { logger.info("Start - GoogleOAuth2Interceptor $request, $response, $handler") val handerMethod = handler as HandlerMethod // アノテーションが付与されている場合、認証チェックを行う。 val annotation = handerMethod.getMethodAnnotation(GoogleOAuth2::class.java) annotation?.let { logger.info("Check Google OAuth2....") // アクセストークンの有無を確認 if(googleCredential.accessToken.isNullOrBlank()) { logger.info("No accessToken. Redirect Google Authentication Server") // アクセストークンがない場合は認証用URLを生成してリダイレクトする val requestUrl = AuthorizationCodeRequestUrl(googleClientSecrets.details.authUri, googleClientSecrets.details.clientId) .setRedirectUri(googleClientSecrets.details.redirectUris.first()) .setScopes(SCOPES) .build() response.sendRedirect(requestUrl) return false } logger.info("AccessToken has found. Continue.") } return true } override fun postHandle(request: HttpServletRequest, response: HttpServletResponse, handler: Any, modelAndView: ModelAndView?) { logger.info("End - GoogleOAuth2Interceptor") super.postHandle(request, response, handler, modelAndView) } }
@RestController class CalendarController( private val googleCredential: GoogleCredential, private val googleClientSecrets: GoogleClientSecrets, private val googleAuthorizationCodeFlow: GoogleAuthorizationCodeFlow, private val calendarService: CalendarService) { private val logger = LoggerFactory.getLogger(javaClass) @GetMapping("/schedule/daily") @GoogleOAuth2 // 認証を行うエンドポイントにアノテーションを付与 fun todaySchedule(): Schedule { val schedule = calendarService.getSchedule(1L) return schedule } // コールバック用エンドポイント @GetMapping("/callback") fun callback(code: String, scope: String): String { // 認証コードをもとにアクセストークンを取得 val request = googleAuthorizationCodeFlow.newTokenRequest(code) .setRedirectUri(googleClientSecrets.details.redirectUris.first()) val response = request.execute() googleCredential.setAccessToken(response.accessToken) return "This is endpoint for google oauth2 callback." } }
すべてのコードはGithubにも掲載しています。
過労で腕を痛めた話と治した話
突然ですが、腕を痛めました。。。 診断結果は疲労による上腕骨外側上顆炎と上腕骨内側上顆炎。文字からだとわかりずらいですが肘の周りです。通称テニス肘と言われるそうですね。
ソフトウェアエンジニアという仕事の性質上よくある話なのかもしれません。が、実際になってみると結構きつかったです。幸いなことに一ヶ月程度で良くなってきたので、ここでは腕を痛めるまでと痛めてから治すまでにやったことを書いていきます。
※ 前提として(そして会社の名誉のためにも)、いわゆる長時間労働が続いていたということはありませんでした。ごく普通に働いており、見た目上なんら問題のなさそうな生活をしていました。
発症一週間前
「なんか右腕がヒリヒリするなあ」というのがきっかけでした。普通にしている分には問題ないんだけど、仕事をしていると夕方〜夜にかけて肘の辺りに違和感が出てくる。なんとなくヒリヒリする。
特に心当たりもなかったのと、仕事ができないほどの痛みではなかったので、あまり気にせずいつもどおり仕事をし、いつもどおり生活をしていました。このくらいの痛みならそのうち消えるでしょ、という気分で。
そう、来週その痛みがさらに悪化するとも知らずに....(怖い話風)
翌週
腕に抱えている違和感が明確な痛みに変わり始めました。え、痛い。本当に痛い。 仕事でタイピングをしていると痛いし、Macbookのトラックパッドをいじいじしているのも痛い。
肘の辺りだけ痛かったのが、手首のあたりも痛くなり、挙げ句の果てには指がつりそうになる始末。
当たり前のことなんですが腕が痛いというのはすごく不便で、仕事はもちろん私生活にも支障をきたしました。家でPC触ることができない、ゲームが遊べない、くらいならまだいいですが、何気ない動作が全て辛い。食器を洗うのがつらい、歯磨きがきつい。何もしてなくても痛いので何をする気にもなれない。利き腕だったので余計にそう感じたのかもしれません。
「これはまずい」と思ってお休みを取り、以前腱鞘炎になった知り合いが勧めてくれた手の専門外科へと行きました。
診断結果
お医者さんには「ジョウワンコツガイソクジョウカエン、ジョウワンコツナイソクジョウカエン。疲労だね。」と言われました。耳で聞いたときには何を言っているか全く変換できなかったのですが、漢字に直すと上腕骨外側上顆炎と上腕骨内側上顆炎。最初にも書きましたがいわゆるテニス肘だそうです。別にテニスなんてしないのになーと調べてたら「スマホ肘」「PC肘」という呼び方も見つけました。ある意味現代病の一種で、普段の生活で疲労が溜まって肘周りの筋肉が炎症を起こしている状態とのこと。

https://www.saiseikai.or.jp/medical/disease/lateral_humeral_epicondylitis/
肘の周りは手首や指につながる筋肉が集まっているため、ここを痛めるといろんな箇所に影響が出るのだとか。実際悪化したあとは手首や指、前腕全体がきしむような痛みを覚えました。インフルエンザにかかると関節が痛くなりますが、あの感覚に近いです。
治すためにやったこと
治すためにいくつかのことを行いました。
この中のどれが一番効いたとかは正直わからないです。全部やってみた結果良くなったのかもしれません。
もちろん、個人の経験ですのでやったことが完全に他の人に合うとは思いません。あくまで参考程度に。
1. 働き方を変える
腕を痛めたあと上長に相談する機会があったので、正直に話をして新規の開発などコーディングが増える作業を減らしてもらいました。 負荷をかけすぎない、ということに重点をおいて業務調整をしてもらい、主にコードレビューや運用周りのタスクをメインにこなすようになりました。
また、弊社はフレックス制度があるため通常の勤務より早めに上がることもできました。朝一番は問題ないけど、6〜7時間程度で腕の限界が来るので、チームメンバーと相談して仕事を調整しつつ、短めの勤務とさせてもらっていました。
2. 治療、リハビリ、ストレッチをする
病院からはロキソニン湿布を処方されてたのでそれを毎日上腕部分に貼っていました。
病院に勧められて超音波治療も行っていました。1回5〜10分程度で診療とは別で行ってもらえるので待つ必要がなかったのも嬉しかったです。週2〜3の頻度で通いました。
また、テニス肘に効きそうなストレッチも行いました。医者からはストレッチをするのは問題ないと言われていたので[*1]、「テニス肘 ストレッチ」で調べて出てきたものを試していました。
www.youtube.com 実際にやってみるとたしかに肘周りの筋肉が伸びている感じがする...
3. キーボードを変える
働き方とは別でもう一個、働く環境を変えました。具体的にはMacbookのキーボードが辛かったので自宅からキーボードを持ってきました。
Kinesis Freestyle 2 という左右分離式のキーボードです。

3ヶ月ほど前に肩こりの改善を目的に自宅用に購入し使っていたのですが、会社に持ってきて使うようになりました。左右が別れているので腕のポジションが自然なままタイピングができるのと、サポートキットによって手の角度を水平ではなく少し傾けた状態で使えるので、通常のノートPCをタイピングするより疲れにくいのが圧倒的なメリットです。
会社のPCゲーマーな同僚には「こんなキーボードで絶対にゲームしたくない」と酷評されましたが、コーディングをする分にはこちらの方が良いと思います。長時間デスクで作業をしたあとの腕から肩周りの疲れが違います。(だんだん宣伝ぽくなってきましたが)おすすめです。
追記: 効かなかったもの - サポーター
診断を受けたときに「どうすればいいでしょう?」と聞いたら「仕事をしないわけにもいかないだろうし、サポーターを付けるとかがいいかなあ」とお医者さんにぼやかれたんで肘周りのサポーターを購入しました。
が、これは僕にとってはあまり良くなかったと思います。たしかに仕事中の痛みは軽減できるんですが、痛みが軽減している分無理に働くことができてしまい、仕事が終わってサポーターを外したあとにすごく痛むということが何度かありました。ドーピングのような感じで自分には良くないなと思ったんで、何回か使ったあとはサポーター無しで生活し、痛くなってきたらきちんと休む、という方向に倒しました。
まとめ: 良くなってきた(気がする)
上記のような取り組みを並行して進めた結果、二週間程度で日常生活が送れるほど腕の痛みはやわらぎ、一ヶ月経った現在痛みはほとんどなくなりました。もちろん長時間コーディングをするなど負荷をかけるとやや違和感を感じる〜ヒリヒリする程度にはなってしまいますが、一番痛かったときと比較すると大きな改善です。
もともと身体が硬かったり医者からストレートネックだと言われたりと、疲労が溜まりやすい & 身体に出やすい体質なので、これからも無理をせず気をつけて働きたい(働きたくない)と思います。
*1:腱鞘炎など症状によっては「ストレッチをすることで悪化する」ケースもあるそうなので医者とよく相談をしたほうがいいです
Clean Architectureを読んだ話
「Clean Architecture 達人に学ぶソフトウェアの構造と設計 」を読んだので感想をば。
")
Clean Architecture 達人に学ぶソフトウェアの構造と設計 (アスキードワンゴ)
- 作者: RobertC.Martin,角征典,高木正弘
- 出版社/メーカー: ドワンゴ
- 発売日: 2018/08/01
- メディア: Kindle版
- この商品を含むブログを見る
どういう本か
名前通りアーキテクチャに関する本ではあるが、この本の特徴は「良いアーキテクチャとはこういうものだ」というトップダウンな説明ではなく、「意識するべき原則は常に同じであり、それをどのように適用していくか」というボトムアップ方式でコアとなる考え方を丁寧に伝えているところだと思います。
どんな種類のシステムでもソフトウェアアーキテクチャのルールは同じ。ソフトウェアアーキテクチャのルールとは、プログラムの構成要素をどのように組み立てるかのルールである。構成要素は普遍的で変わらないのだから、それらを組み立てるルールもまた、普遍的で変わらないのである。
序文にこう書かれているように、本書前半ではSOLID原則に始まり、様々なソフトウェア設計の原則を丁寧に説明していきます。これらの原則は後半の本題であるコンポーネントやアーキテクチャの話の中で具体例を交えながら何度も出てくるため、読者は基礎と応用の結びつき方が自然と理解でき、「なぜ」がすっと頭に入ってきます。
原則の説明→具体例の紹介→抽象化というサイクルが本書の中でうまく回されており、読んでいく中でエンジニアとして一段上の視野が拓けるようになると思います。
どういう人が読むとよいか
もちろんソフトウェアエンジニアリングに関わるいろんな人に読んでもらいたいですが、個人的にはプログラマとしてそれなりの経験があり、設計も含めて一からサービス開発にチャレンジしたことのある人が自身の経験と照らし合わせて読むと大きな気付きが得られるのではと思います。もちろんそれだけではなく、SOLID原則やデザインパターン、アーキテクチャの原則に関する基本的な知識はあるものの、実践でうまく活かせないというモヤモヤを抱えている人にとっても非常にためになるような本だと思います。
また、ビジネスロジックの扱いなどドメイン駆動開発(DDD)の考え方について理解するにも良い本でした。いわゆるDDD本はそれはそれで素晴らしいのですが、挫折してしまった人、理想だと割り切って読んでしまった人にとってこの本は理想と現実を繋いでくれることでしょう。
個人的に良かった点
僕がこの本を読んだタイミングは、中長期かけて取り組んでいた新サービスの立ち上げが終わったタイミングでした。自分の中で色んな葛藤や反省を抱えていた時期だったので、それをうまく言語化し次に活かしていくのに非常に刺さりました。
印象に残った文章
一番印象に残ったのは以下の文章です。
そもそもソフトウェアアーキテクトはプログラマである。(中略)ソフトウェアアーキテクトは最高のプログラマであり、継続してプログラミングの仕事を引き受けながら、生産性を最大化する設計にチームを導いていく。(15章アーキテクチャとは? より)
これは非常に大事で、プログラマだろうとアーキテクトだろうと忘れてはいけないことだと思います。そもそも良いアーキテクチャを作るのは自己満足のためではなく、プロダクトの保守性を向上させ、ビジネス価値を高めていくためです。プロダクトの保守、改善が容易というのは既存のコードに手を入れやすいことと同義で、具体的な実装の積み重ねが良いアーキテクチャを構成していきます。上記の文章はなんとなく自分が思い描いていたアーキテクト像と近かったのでとても響きました。
現実に立ち向かう方法を教えてくれる
冒頭にも書いたようにこの本では非常に多様な具体例をもって目指すべき道筋を示してくれます。また、全体を通して「プロジェクトの現状やステータスによって最適解は常に変わる」というスタンスで書かれているため理論の押し付け感がなく、自分たちの現場と照らし合わせて読みやすいというのも本書の特徴です。多くのエンジニアに自分が持っている武器と、その使い方を教えてくれる本だと思います。
おまけ
付録としてついている「アーキテクチャ考古学」は、OSもファイルシステムもなかった時代からエンジニアとして活動してきた筆者の自著伝です。こちらも読み物としてとても面白いのでぜひ読んでみてください。